Security Research Group at IISc Bangalore
Selected Research Highlights
The following are selected research highlights from various labs that are part of the security research group.
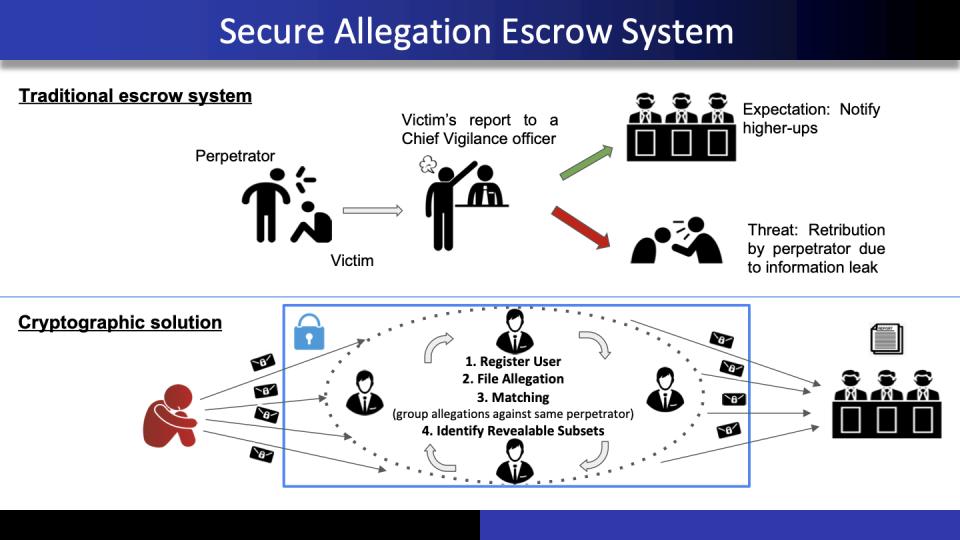
Shield: Secure Allegation Escrow System with Stronger Guarantees
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra's lab together with Nishat Koti, Varsha Bhat Kukkala, and Bhavish Raj Gopal, and appears in the The Web Conference 2023 (WWW '23).
The rising issues of harassment, exploitation, corruption and other forms of abuse have led victims to seek comfort by acting in unison against common perpetrators. This is corroborated by the widespread #MeToo movement, which was explicitly against sexual harassment. Installation of escrow systems to identify common perpetrators allows victims to report such incidents. However, users hesitate to participate fearing the reports being leaked to perpetrators. Thus, to increase trust in the system, cryptographic solutions are being designed to realize secure allegation escrow (SAE) systems. Having identified the attacks and issues in all prior works, we put forth an SAE system that overcomes these while retaining all the existing salient features.
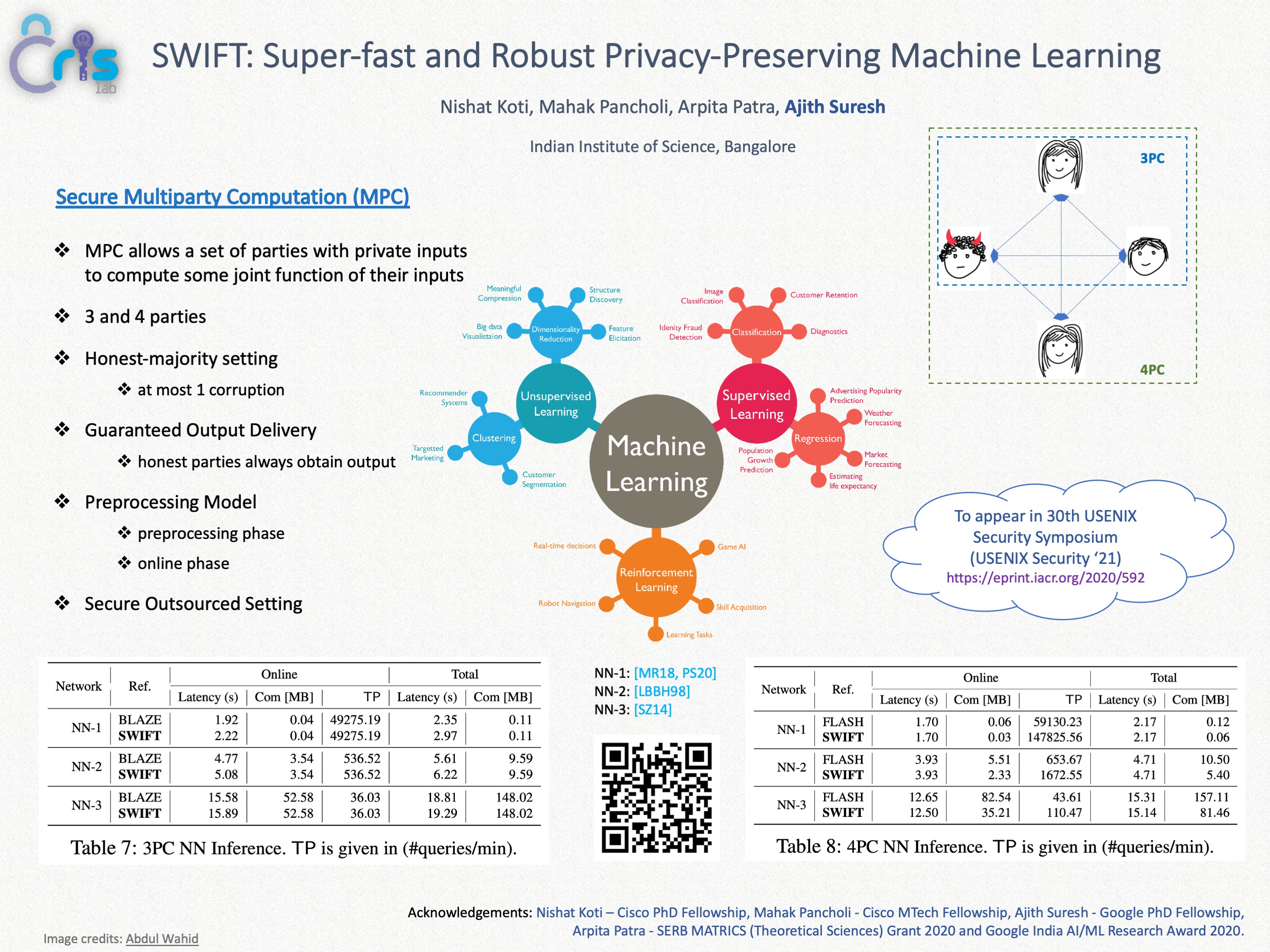
SWIFT: Super-fast and Robust Privacy-Preserving Machine Learning
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra's lab together with Nishat Koti, Mahak Pancholi, and Ajith Suresh, and appears in the 30th USENIX Security Symposium (USENIX Security '21).
Performing machine learning (ML) computation on private data while maintaining data privacy, aka Privacy-preserving Machine Learning (PPML), is an emergent field of research. Recently, PPML has seen a visible shift towards the adoption of the Secure Outsourced Computation (SOC) paradigm due to the heavy computation that it entails. In the SOC paradigm, computation is outsourced to a set of powerful and specially equipped servers that provide service on a pay-per-use basis. In this work, we propose SWIFT, a robust PPML framework for a range of ML algorithms in SOC setting, that guarantees output delivery to the users irrespective of any adversarial behaviour. Robustness, a highly desirable feature, evokes user participation without the fear of denial of service.
At the heart of our framework lies a highly-efficient, maliciously-secure, three-party computation (3PC) over rings that provides guaranteed output delivery (GOD) in the honest-majority setting. To the best of our knowledge, SWIFT is the first robust and efficient PPML framework in the 3PC setting. SWIFT is as fast as (and is strictly better in some cases than) the best-known 3PC framework BLAZE (Patra et al. NDSS'20), which only achieves fairness. We extend our 3PC framework for four parties (4PC). In this regime, SWIFT is as fast as the best known fair 4PC framework Trident (Chaudhari et al. NDSS'20) and twice faster than the best-known robust 4PC framework FLASH (Byali et al. PETS'20).
We demonstrate our framework's practical relevance by benchmarking popular ML algorithms such as Logistic Regression and deep Neural Networks such as VGG16 and LeNet, both over a 64-bit ring in a WAN setting. For deep NN, our results testify to our claims that we provide improved security guarantee while incurring no additional overhead for 3PC and obtaining 2x improvement for 4PC.
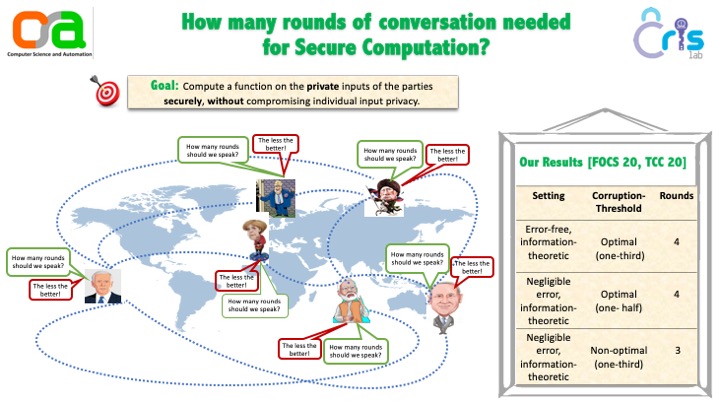
The Resiliency of MPC with Low Interaction: The Benefit of Making Errors
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra's lab together with Benny Applebaum and Eliran Kachlon and appears at TCC 2020.
We study information-theoretic secure multiparty protocols that achieve full security, including guaranteed output delivery, at the presence of an active adversary that corrupts a constant fraction of the parties. It is known that 2 rounds are insufficient for such protocols even when the adversary corrupts only two parties (Gennaro, Ishai, Kushilevitz, and Rabin; Crypto 2002), and that perfect protocols can be implemented in 3 rounds as long as the adversary corrupts less than a quarter of the parties (Applebaum , Brakerski, and Tsabary; Eurocrypt, 2019). Furthermore, it was recently shown that the quarter threshold is tight for any 3-round perfectly-secure protocol (Applebaum, Kachlon, and Patra; FOCS 2020). Nevertheless, one may still hope to achieve a better-than-quarter threshold at the expense of allowing some negligible correctness errors and/or statistical deviations in the security.
Our main results show that this is indeed the case. Every function can be computed by 3-round protocols with statistical security as long as the adversary corrupts less than a third of the parties. Moreover, we show that any better resiliency threshold requires 4 rounds. Our protocol is computationally inefficient and has an exponential dependency in the circuit's depth d and in the number of parties n. We show that this overhead can be avoided by relaxing security to computational, assuming the existence of a non-interactive commitment (NICOM). Previous 3-round computational protocols were based on stronger public-key assumptions. When instantiated with statistically-hiding NICOM, our protocol provides everlasting statistical security, i.e., it is secure against adversaries that are computationally unlimited after the protocol execution.
To prove these results, we introduce a new hybrid model that allows for 2-round protocols with a linear resiliency threshold. Here too we prove that, for perfect protocols, the best achievable resiliency is n/4, whereas statistical protocols can achieve a threshold of n/3. In the plain model, we also construct the first 2-round n/3-statistical verifiable secret sharing that supports second-level sharing and prove a matching lower-bound, extending the results of Patra, Choudhary, Rabin, and Rangan (Crypto 2009). Overall, our results refine the differences between statistical and perfect models of security and show that there are efficiency gaps even for thresholds that are realizable in both models.
The Round Complexity of Perfect MPC with Active Security and Optimal Resiliency
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra's lab together with Benny Applebaum and Eliran Kachlon and appears at FOCS 2020.
In STOC 1988, Ben-Or, Goldwasser, and Wigderson (BGW) established an important milestone in the fields of cryptography and distributed computing by showing that every functionality can be computed with perfect (information-theoretic and error-free) security at the presence of an active (aka Byzantine) rushing adversary that controls up to n/3 of the parties.
We study the round complexity of general secure multiparty computation in the BGW model. Our main result shows that every functionality can be realized in only four rounds of interaction, and that some functionalities cannot be computed in three rounds. This completely settles the round-complexity of perfect actively-secure optimally-resilient MPC, resolving a long line of research.
Our lower-bound is based on a novel round-reduction technique that allows us to lift existing three-round lower-bounds for verifiable secret sharing to four-round lower-bounds for general MPC. To prove the upper-bound, we develop new round-efficient protocols for computing degree-2 functionalities over large fields, and establish the completeness of such functionalities. The latter result extends the recent completeness theorem of Applebaum, Brakerski and Tsabary (TCC 2018, Eurocrypt 2019) that was limited to the binary field.

Beyond Honest Majority: The Round Complexity of Fair and Robust Multi-party Computation
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra and Divya Ravi and appears at ASIACRYPT 2019.
Two of the most sought-after properties of Multi-party Computation (MPC) protocols are fairness and guaranteed output delivery (GOD), the latter also referred to as robustness. Achieving both, however, brings in the necessary requirement of malicious-minority. In a generalised adversarial setting where the adversary is allowed to corrupt both actively and passively, the necessary bound for a n-party fair or robust protocol turns out to be ta+tp < n, where ta,tp denote the threshold for active and passive corruption with the latter subsuming the former. Subsuming the malicious-minority as a boundary special case, this setting, denoted as dynamic corruption, opens up a range of possible corruption scenarios for the adversary. While dynamic corruption includes the entire range of thresholds for (ta,tp) starting from (⌈n/2⌉−1,⌊n/2⌋) to (0,n−1), the boundary corruption restricts the adversary only to the boundary cases of (⌈n/2⌉−1,⌊n/2⌋) and (0,n−1). Notably, both corruption settings empower an adversary to control majority of the parties, yet ensuring the count on active corruption never goes beyond ⌈n/2⌉−1.
We target the round complexity of fair and robust MPC tolerating dynamic and boundary adversaries. As it turns out, ⌈n/2⌉+1 rounds are necessary and sufficient for fair as well as robust MPC tolerating dynamic corruption. The non-constant barrier raised by dynamic corruption can be sailed through for a boundary adversary. The round complexity of 3 and 4 is necessary and sufficient for fair and GOD protocols respectively, with the latter having an exception of allowing 3 round protocols in the presence of a single active corruption. While all our lower bounds assume pair-wise private and broadcast channels and are resilient to the presence of both public (CRS) and private (PKI) setup, our upper bounds are broadcast-only and assume only public setup. The traditional and popular setting of malicious-minority, being restricted compared to both dynamic and boundary setting, requires 3 and 2 rounds in the presence of public and private setup respectively for both fair as well as GOD protocols.
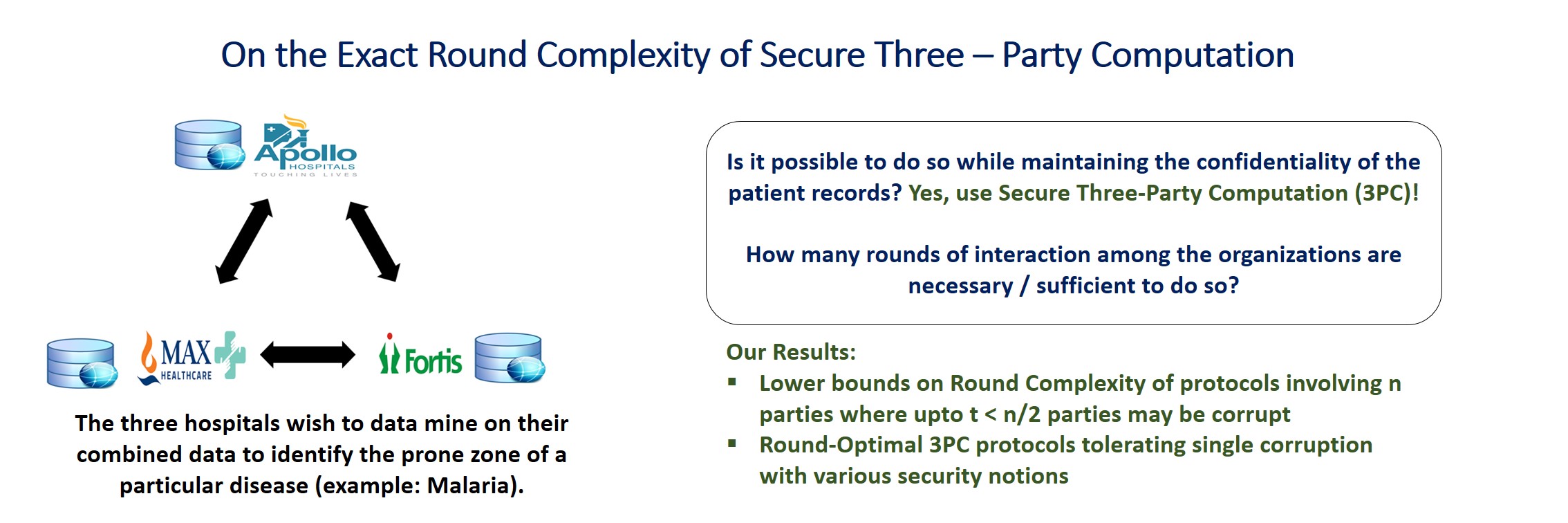
Round Complexity of Secure Three-Party Computation
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Prof. Arpita Patra and Divya Ravi and appears at CRYPTO 2018.
Secure multi-party computation (MPC) allows a set of mutually distrusting parties to jointly perform a computation on their inputs while keeping their inputs private. The study of 3-party setting is interesting as it presents many useful use-cases in practice. In this work, we settle the exact round complexity of three-party computation (3PC) protocols tolerating a single corrupt party, for a range of security notions such as selective abort, unanimous abort, fairness and guaranteed output delivery.
We focus on two network settings-- pairwise-private channels without and with a broadcast channel. In the minimal setting of pairwise-private channels, 3PC with selective abort is known to be feasible in just two rounds, while guaranteed output delivery is infeasible to achieve irrespective of the number of rounds. Settling the quest for exact round complexity of 3PC in this setting, we show that three rounds are necessary and sufficient for unanimous abort and fairness. Extending our study to the setting with an additional broadcast channel, we show that while unanimous abort is achievable in just two rounds, three rounds are necessary and sufficient for fairness and guaranteed output delivery. Our lower bound results extend for any number of parties in honest majority setting. The fundamental concept of garbled circuits underlies all our upper bounds. Concretely, our constructions involve transmitting and evaluating only constant number of garbled circuits. Assumption-wise, our constructions rely on injective (one-to-one) one-way functions.
In more detail, we settle the exact round complexity of three-party computation (3PC) in honest-majority setting, for a range of security notions such as selective abort, unanimous abort, fairness and guaranteed output delivery. Selective abort security, the weakest in the lot, allows the corrupt parties to selectively deprive some of the honest parties of the output. In the mildly stronger version of unanimous abort, either all or none of the honest parties receive the output. Fairness implies that the corrupted parties receive their output only if all honest parties receive output and lastly, the strongest notion of guaranteed output delivery implies that the corrupted parties cannot prevent honest parties from receiving their output. It is a folklore that the implication holds from the guaranteed output delivery to fairness to unanimous abort to selective abort. We focus on two network settings-- pairwise-private channels without and with a broadcast channel.
In the minimal setting of pairwise-private channels, 3PC with selective abort is known to be feasible in just two rounds, while guaranteed output delivery is infeasible to achieve irrespective of the number of rounds. Settling the quest for exact round complexity of 3PC in this setting, we show that three rounds are necessary and sufficient for unanimous abort and fairness. Extending our study to the setting with an additional broadcast channel, we show that while unanimous abort is achievable in just two rounds, three rounds are necessary and sufficient for fairness and guaranteed output delivery. Our lower bound results extend for any number of parties in honest majority setting and imply tightness of several known constructions.
The fundamental concept of garbled circuits underlies all our upper bounds. Concretely, our constructions involve transmitting and evaluating only constant number of garbled circuits. Assumption-wise, our constructions rely on injective (one-to-one) one-way functions.
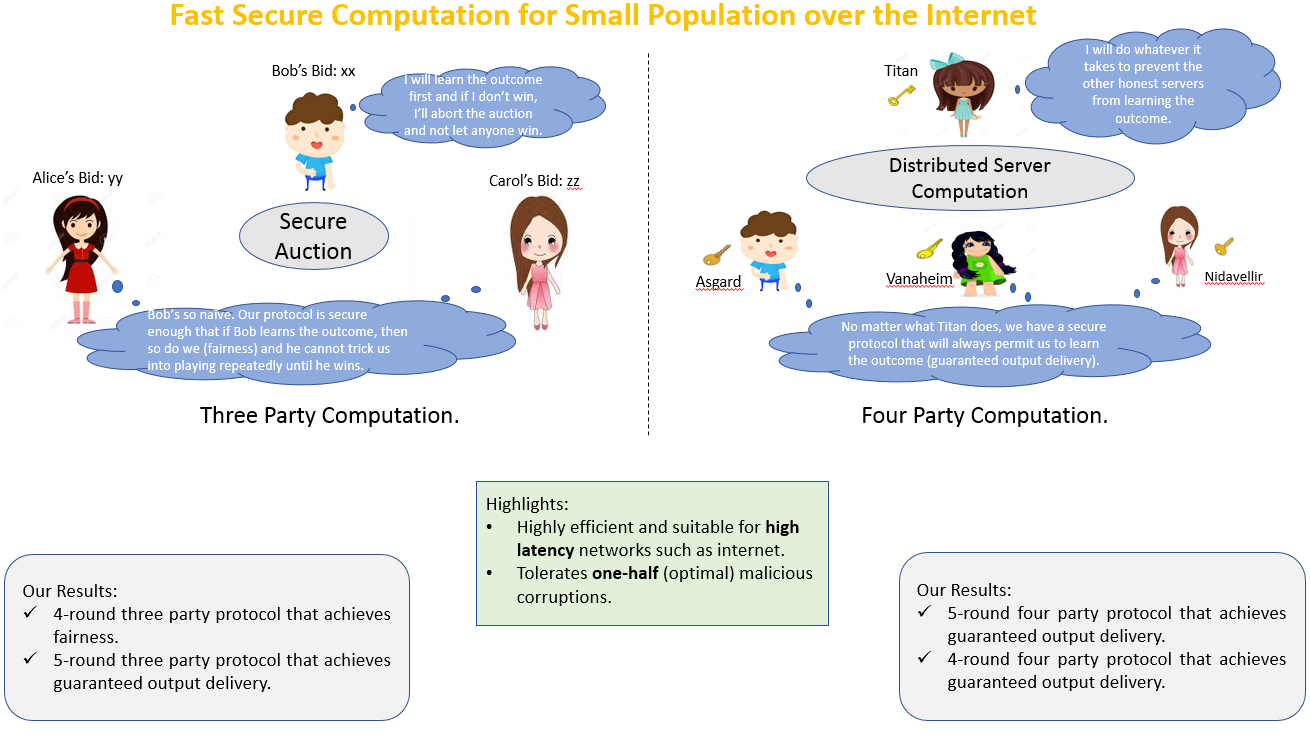
Fast Secure Computation for Small Populations over the Internet
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done in Prof. Arpita Patra's lab together with Megha Byali, Arun Joseph, and Divya Ravi, and appears in the ACM Conference on Computer and Communications Security 2018.
The area of Secure MultiParty Comptation (MPC) with small number of parties in the honest majority setting (majority of the parties are honest) has drawn popularity particularly due to simplicity and efficiency of the resulting protocols. The area is worthwhile to explore due to the following reasons. First, most real-time applications involve small number of parties. For instance, applications such as statistical data analysis, email-filtering, financial data analysis, distributed credential encryption, Danish sugar beet auction involve 3 parties. Second, for the instance of large-scale computation on data involving sensitive information, it is preferable to utilize 3 or 4 servers in comparison to only two for improved fault-tolerance and performance. Another crucial advantage of honest majority is enabling stronger security goals such as fairness (corrupted parties receive their output only if all honest parties receive output) and guaranteed output delivery (corrupted parties cannot prevent honest parties from receiving their output) which are attainable only in the honest majority setting. These goals are desirable in practical applications as they serve as a stimulant for parties to be engaged in the computation. Also, having honest majority is advantageous to obtain constructions relying on weaker cryptographic assumptions and light-weight cryptographic tools.
In this paper, we provide highly efficient constructions for the setting of 3-party and 4-party computations, secure against one corruption that achieve fairness and guaranteed output delivery. Being constant round, our protocols are suitable for high latency networks such as the Internet. We present efficient, constant-round 3-party (3PC) and 4-party (4PC) protocols in the honest-majority setting that achieve strong security notions of fairness (corrupted parties receive their output only if all honest parties receive output) and guaranteed output delivery (corrupted parties cannot prevent honest parties from receiving their output). Being constant-round, our constructions are suitable for Internet-like high-latency networks and are built from garbled circuits (GC).
Assuming the minimal model of pairwise-private channels, we present two protocols that involve computation and communication of a single GC-- (a) a 4-round 3PC with fairness, (b) a 5-round 4PC with guaranteed output delivery. Empirically, our protocols are on par with the best known 3PC protocol of Mohassel et al. [CCS 2015] that only achieves security with selective abort, in terms of the computation time, LAN runtime, WAN runtime and communication cost. In fact, our 4PC outperforms the 3PC of Mohassel et al. significantly in terms of per-party computation and communication cost. With an extra GC, we improve the round complexity of our 4PC to four rounds. The only 4PC in our setting, given by Ishai et al. [CRYPTO 2015], involves 12 GCs.
Assuming an additional broadcast channel, we present a 5-round 3PC with guaranteed output delivery that involves computation and communication of a single GC. A broadcast channel is inevitable in this setting for achieving guaranteed output delivery, owing to an impossibility result in the literature. The overall broadcast communication of our protocol is nominal and most importantly, is independent of the circuit size. This protocol too induces a nominal overhead compared to the protocol of Mohassel et al.
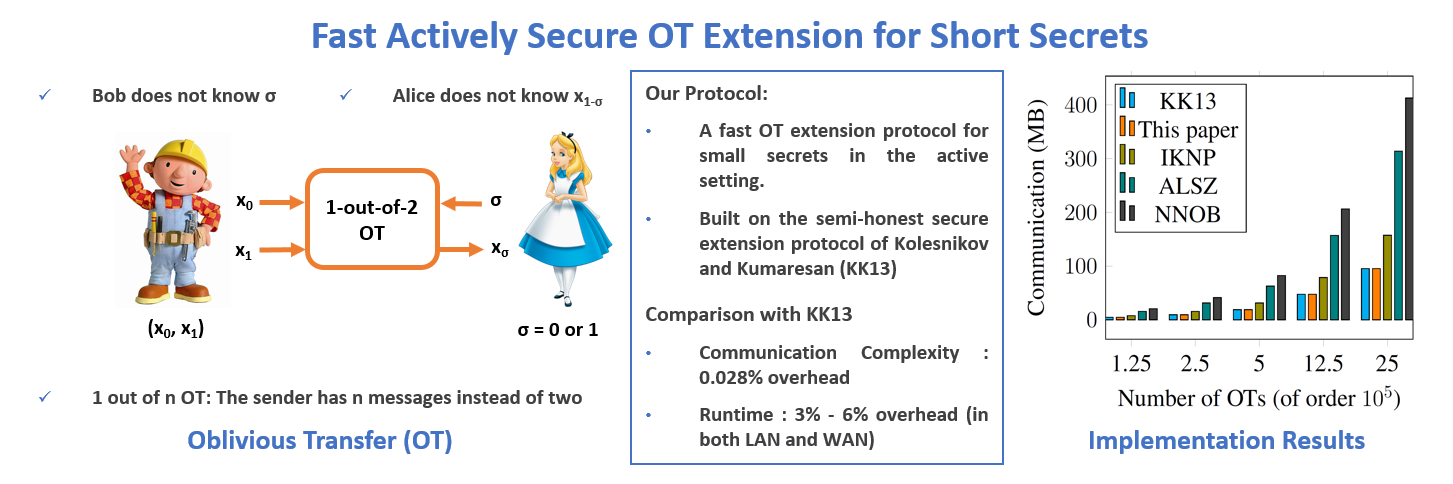
Fast Actively Secure Oblivious Transfer Extension for Short Secrets
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Arpita Patra, Pratik Sarkar, and Ajith Suresh and published at the 2017 Networked and Distributed Systems Security Symposium (NDSS 2017)
Oblivious Transfer (OT) is one of the most fundamental cryptographic primitives with wide-spread application in general secure multi-party computation (MPC) as well as in several tailored and special-purpose problems of interest such as private set intersection (PSI), private information retrieval (PIR), contract signing to name a few. Often the instantiations of OT require prohibitive communication and computation complexity. OT extension protocols are introduced to compute a very large number of OTs referred as extended OTs at the cost of a small number of OTs referred as seed OTs. The work focuses on constructing a blazing fast efficient OT extension protocol that boosts the security of existing state-of-the-art protocols with minimal overhead. Concretely, our protocol when used to generate large enough number of OTs adds only 0.011-0.028% communication overhead and 4-6% runtime overhead both in LAN and WAN setting.

Almost-Surely Terminating Asynchronous Byzantine Agreement
Relevant lab: Cryptography and Information Security Lab (Prof. Arpita Patra)
This work was done by Laasya Bangalore, Ashish Choudhury, and Arpita Patra, and appears at PODC’18, the ACM Symposium on Principles of Distributed Computing 2018.
The problem of Byzantine Agreement (BA) is of interest to both distributed computing and cryptography community. Following well-known results from the distributed computing literature, BA in the asynchronous network setting encounters inevitable non-termination issues. The impasse is overcome via randomization that allows construction of BA protocols in two flavours of termination guarantee – with overwhelming probability and with probability one. The latter type termed as almost-surely terminating BAs are the focus of this paper. An eluding problem in the domain of almost-surely terminating BAs is achieving a constant expected running time. Our work makes progress in this direction. In a setting with n parties and an adversary with unbounded computing power controlling atmost t parties (who can deviate from the protocol in any manner), we present two almost-surely terminating BA protocols in the asynchronous setting. Our first protocol runs in expected time linear in n and tolerates optimal corrupt parties i.e. t < n/3. Existing protocols in this setting either run for expected quadratic (in n) time or exponential computing power from the honest parties. In terms of communication complexity, our construction outperforms all known constructions that offer almost-surely terminating feature. Our Second protocol runs in constant expected running time (independent of n) and tolerates slightly less than one-third corrupt parties i.e. t < n/(3 + ε) for some constant ε > 0. The known constructions with constant expected running time either require ε ≥ 1 implying t < n/4 or calls for exponential computing power from the honest parties.
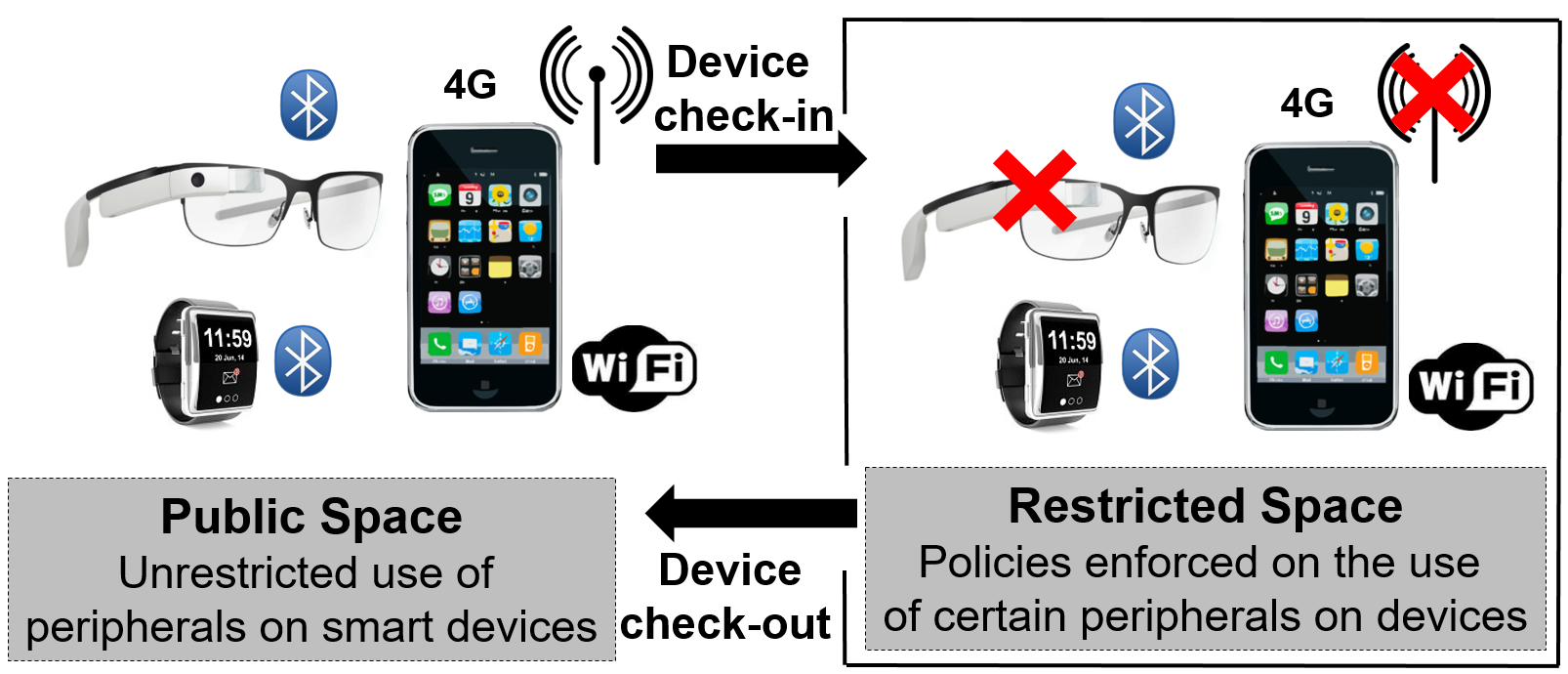
Regulating Smart Devices in Restricted Spaces
Relevant lab: Computer Systems Security Lab (Prof. Vinod Ganapathy)
This work appears in the 2016 ACM International Conference on Mobile Systems, Applications and Services (MobiSys 2016).
Personal computing devices, such as phones, tablets, glasses, watches, assistive health monitors and other embedded devices have become an integral part of our daily lives. We carry these devices as we go, and expect them to connect and work with the environments that we visit. While the increasing capability of smart devices and universal connectivity are generally desirable trends, there are also environments where these trends may be misused. In enterprise settings and federal institutions, for instance, malicious personal devices can be used to exfiltrate sensitive information to the outside world. In examination settings, smart devices may be used to infiltrate unauthorized information, surreptitiously collude with peers and cheat on the exam. Even in less stringent social settings, smart devices may be used to record pictures, videos or conversations that could compromise privacy. We therefore need to regulate the use of smart devices in such restricted spaces.
Society currently relies on a number of ad hoc methods for policy enforcement in restricted spaces. In the most stringent settings, such as in federal institutions, employees may be required to place their personal devices in Faraday cages and undergo physical checks before entering restricted spaces. In corporate settings, employees often use separate devices for work and personal computing needs. Personal devices are not permitted to connect to the corporate network, and employees are implicitly, or by contract, forbidden from storing corporate data on personal devices. In examination settings, proctors ensure that students do not use unauthorized electronic equipment. Other examples in less formal settings include restaurants that prevent patrons from wearing smart glasses, or privacy-conscious individuals who may request owners to refrain from using their devices.
We posit that such ad hoc methods alone will prove inadequate given our increasing reliance on smart devices. For example, it is not possible to ask an individual with prescription smart glasses (or any other assistive health device) to refrain from using the device in the restricted space. The right solution would be to allow the glass to be used as a vision corrector, but regulate the use of its peripherals, such as the camera, microphone, or WiFi. A general method to regulate the use of smart devices in restricted spaces would benefit both the hosts who own or control the restricted space and guests who use smart devices. Hosts will have greater assurance that smart devices used in their spaces conform to their usage policies. On the other hand, guests can benefit from and be more open about their use of smart devices in the host's restricted space.
Our vision is to enable restricted space hosts to enforce usage policies on guest devices with provable security guarantees. Simultaneously, we also wish to reduce the amount of trusted policy-enforcement code (i.e., the size of the security-enhanced software stack) that needs to execute on guest devices. To that end, this project leverages the ARM TrustZone on guest devices to offer provable security guarantees. In particular, a guest device uses the ARM TrustZone to produce verification tokens, which are unforgeable cryptographic entities that establish to a host that the guest is policy-compliant. Malicious guest devices, which may have violated the host's policies in the restricted space, will not be able to provide such a proof, and can therefore be apprehended by the host. Devices that use the ARM TrustZone are now commercially available and widely deployed, and our approach applies to these devices.
We built and evaluated a prototype to show the benefits of our approach. We show that a small policy-enforcing code base running on guest devices offers hosts fine-grained policy-based control over the devices. We also show that a vetting service with a few simple sanity checks allows guests to ensure the safety of the host's policy enforcement of guest devices.
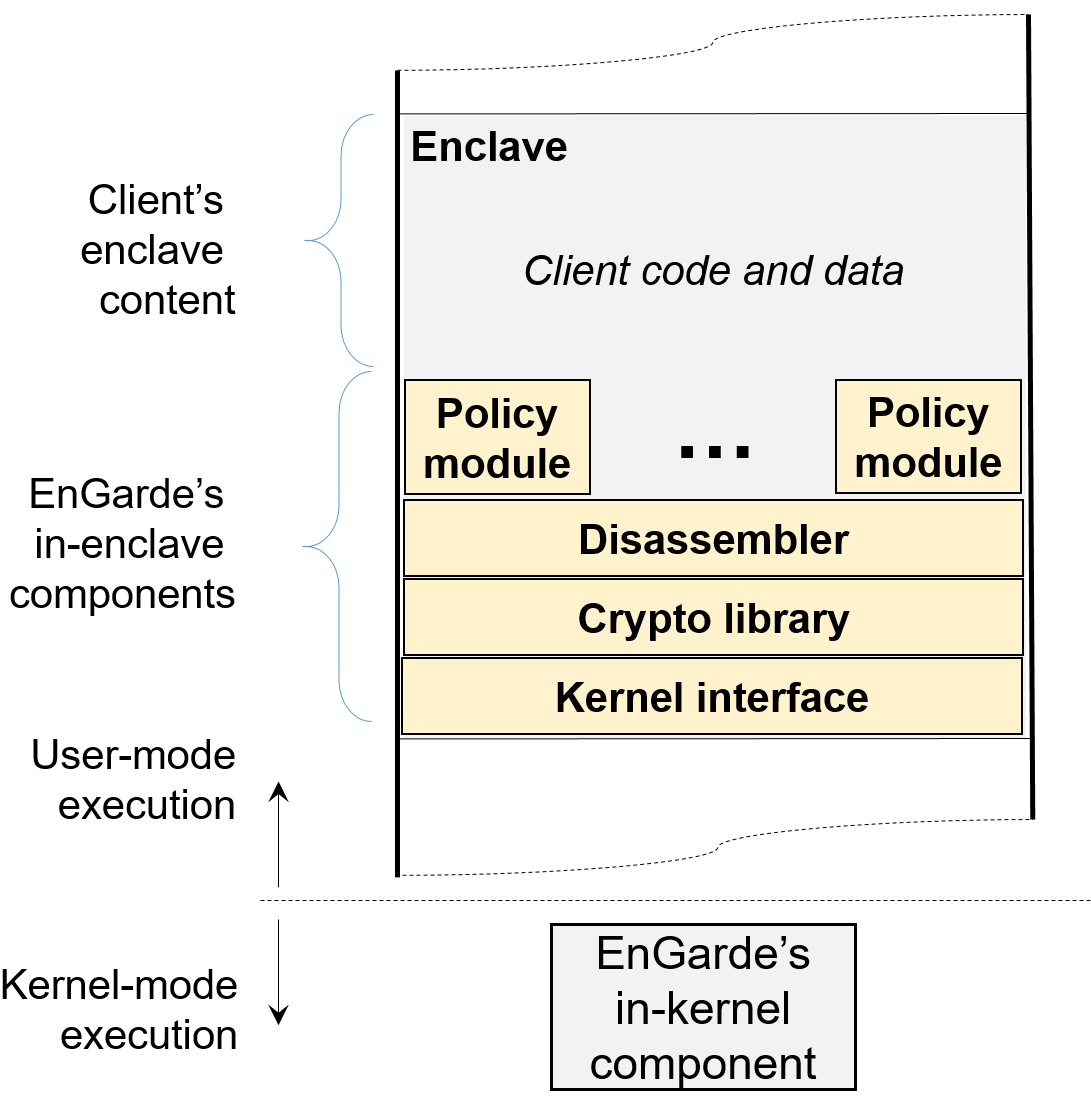
Secure and Private Cloud Computing with Trusted Hardware
Relevant lab: Computer Systems Security Lab (Prof. Vinod Ganapathy)
This work appears in the 2017 International Conference on Distributed Computing Systems (ICDCS 2017)
In recent years, the research community has devoted much attention to security and privacy threats that arise in public cloud computing platforms, such as Amazon EC2 and Microsoft Azure. From the perspective of cloud clients, one of the chief security concerns is that the computing infrastructure is not under the client’s control. While relinquishing control frees the client from having to procure and manage computing infrastructure, it also exposes the client’s code and data to cloud providers and administrators. Malicious cloud administrators can compromise client confidentiality by reading sensitive code and data directly from memory highlights_scroll of the client’s virtual machines (VM). They could also inject malicious code into client VMs, e.g., to insert backdoors or log keystrokes, thereby compromising integrity. Even otherwise honest cloud providers could be forced to violate client trust because of subpoenas.
Intel’s SGX architecture offers hardware support to alleviate such client security and privacy concerns. SGX allows client processes and VMs to create enclaves, within which they can store and compute on sensitive data. Enclaves are encrypted at the hardware level using hardware-managed keys. SGX guarantees that enclave content that includes enclave code and data is not visible in the clear outside the enclave, even to the most privileged software layer running on the system, i.e., the operating system (OS) or the hypervisor. SGX also offers support for enclave attestation, thereby providing assurances rooted in hardware that an enclave was created and bootstrapped securely, without interference from the cloud provider. With SGX, clients can therefore protect the confidentiality and integrity of their code and data even from a malicious cloud provider or administrator, so long as they are willing to trust the hardware.
Despite these benefits, SGX has the unfortunate consequence of flipping the trust model that is prevalent on contemporary cloud platforms. On non-SGX platforms, a benign cloud provider benefits from the ability to inspect client code and data. The cloud provider can provide clients with services such as malware detection, vulnerability scanning, and memory deduplication. Such services are also beneficial to benign clients. The cloud provider can check client VMs for service-level agreement (SLA) compliance, thereby catching malicious clients who may misuse the cloud platform in various ways, e.g., by using it to host a botnet command and control server. In contrast, on an SGX platform, the cloud provider can no longer inspect the content of a client’s enclaves. This affects benign clients, who can no longer avail of cloud-based services for their enclaves. It also benefits malicious clients by giving them free reign to perform a variety of SLA-violating activities within enclaves. Researchers have discussed the possibility of such "detection-proof" SGX malware. Without the ability to inspect the client’s code, the cloud provider is left to using other, indirect means to infer the presence of such malicious activities.
SGX while still allowing the cloud provider to exert some control over the content of the client’s enclaves? One strawman solution to achieve this goal is to use a trusted-third party (TTP). Both the cloud provider and client would agree upon a certain set of policies/constraints that the enclave content must satisfy (as is done in SLAs). For example, the cloud provider could specify that the enclave code must be certified as clean by a certain anti-malware tool, or that the enclave code be produced by a compiler that inserts security checks, e.g., to enforce control-flow integrity or check for other memory access violations. They inform the TTP about these policies, following which the client discloses its sensitive content to the TTP, which checks for policy compliance. The cloud provider then allows the client to provision the enclave with this content.
However, the main drawback of this strawman solution is the need for a TTP. Finding such a TTP that is acceptable to both the cloud provider and the client is challenging in realworld settings, thereby hampering deployability. TTPs could themselves be subject to government subpoenas that force them to hand over the client’s sensitive content. From the client’s perspective, this solution provides no more security than handing over sensitive content to the cloud provider.
In this work, we present EnGarde, an enclave inspection library that achieves the above goal without TTPs. Cloud providers and clients agree upon the policies that enclave code must satisfy and encode it in EnGarde. Thus, cloud providers and clients mutually trust EnGarde with policy enforcement. The cloud provider creates a fresh enclave provisioned with EnGarde, and proves to the client, using SGX’s hardware attestation, that the enclave was created securely. The client then hands its sensitive content to EnGarde over an encrypted channel. It provisions the enclave with the client’s content only if the content is policycompliant. If not, it informs the cloud provider, who can prevent the client from creating the enclave.
EnGarde’s approach combines the security benefits of non-SGX and SGX platforms. From the cloud provider’s perspective, it is able to check client computations for policy-compliance, as in non-SGX platforms. From the client’s perspective, its sensitive content is not revealed to the cloud provider, preserving the security guarantee as offered by SGX platforms. Moreover, EnGarde statically inspects the client’s enclave content only once—when the enclave is first provisioned with that content. One can also imagine an extension of EnGarde that instruments client code to enforce policies at runtime, but our current implementation only implements support for static code inspection. Thus, except for a small increase in enclaveprovisioning time, EnGarde does not impose any runtime performance penalty on the client’s enclave computations. We have implemented a prototype of EnGarde and have used it to check a variety of security policies on a number of popular open-source programs running within enclaves.

Analysis of Concurrent Software
Relevant lab: Software Engineering and Analysis Lab (Prof. Aditya Kanade)
Event-driven concurrent programming is central in many software domains such as smartphone applications, web browsers and cloud applications. While it makes software responsive and scalable, programmers have to deal with resulting non-determinism. The SEAL research group has developed foundational algorithmic techniques for finding bugs or proving their correctness. We have developed and released program analysis tools (www.iisc-seal.net/software) through which we found 50+ real bugs that were subsequently fixed by the developers. This work appears in several papers:
- Race detection for Android applications, P. Maiya et al. [PLDI 2014]
- Static deadlock detection for asynchronous C# applications, A. Santhiar et al. [PLDI 2017]
- Event-based concurrency: Applications, abstractions and analyses, A. Kanade [Invited book chapter, Advances in Computers, 2018]
For example, the PLDI 2017 paper above addresses the following problem. Asynchronous programming is a standard approach for designing responsive applications. Modern languages such as C# provide async/await primitives for the disciplined use of asynchrony. In spite of this, programs can deadlock because of incorrect use of blocking operations along with non-blocking (asynchronous) operations. While developers are aware of this problem, there is no automated technique to detect deadlocks in asynchronous programs.
This work presents a novel representation of control flow and scheduling of asynchronous programs, called continuation scheduling graph and formulate necessary conditions for a deadlock to occur in a program. We design static analyses to construct continuation scheduling graphs of asynchronous C# programs and to identify deadlocks in them. We have implemented the static analyses in a tool called DeadWait. Using DeadWait, we found 43 previously unknown deadlocks in 11 asynchronous C# libraries. We reported the deadlocks to the library developers. They have confirmed and fixed 40 of them.

Automatic Bug-Fixing in Programs
Relevant lab: Software Engineering and Analysis Lab (Prof. Aditya Kanade)
Software developers spend enormous time in finding and fixing bugs. Can we assist them in fixing tedious bugs? The SEAL research group has developed innovative techniques that combine program analysis and machine/deep learning to assist developers and student programmers automatically fix software bugs. The resulting tools (www.iisc-seal.net/software ) have been evaluated on benchmark industrial programs and student code. This work appears in several papers:
- MintHint: Automated synthesis of repair hints, S. Kaleeswaran et al. [ICSE 2014]
- Semi-supervised verified feedback generation, S. Kaleeswaran et al. [FSE 2016]
- DeepFix: Fixing common C language errors by deep learning, R. Gupta et al. [AAAI 2017]
For example, the AAAI 2017 paper referenced above address the problem of debugging programming errors, which is one of the most time-consuming activities for programmers. Therefore, the problem of automatically fixing programming errors, also called program repair, is a very active research topic in software engineering (Monperrus 2015). Most of the program repair techniques focus on logical errors in programs. Using a specification of the program (such as a test suite or an assertion), they attempt to fix the program. Since their focus is on fixing logical errors in individual programs, they assume that the program compiles successfully.
This leaves a large and frequent class of errors out of the purview of the existing techniques. These include errors due to missing scope delimiters (such as a closing brace), adding extraneous symbols, using incompatible operators or missing variable declarations. Such mistakes arise due to programmer’s inexperience or lack of attention to detail, and cause compilation or build errors. Not only novice students but experienced developers also make such errors as found in a study of build errors at Google (Seo et al. 2014). We call them common programming errors. These are common in the sense that, unlike logical errors, they are not specific tothe programming task at hand, but relate to the overall syntax and structure of the programming language. These are analogous to grammatical errors in natural languages.
This work proposes to fix common programming errors by deep learning. Because of the inter-dependencies among different parts of a program, fixing even a single error may require analysis of the entire program. This makes it challenging to fix them automatically. The accuracy bar is also quite high for program repair. The usual notion of token-level accuracy is much too relaxed for this setting. For a fix to be correct, the repair tool must produce the entire sequence pertaining to the fix precisely.
This work presents an end-to-end solution, called DeepFix, that does not use any external tool to localize or fix errors. We use a compiler only to validate the fixes suggested by DeepFix. At the heart of DeepFix is a multi-layered sequenceto-sequence neural network with attention (Bahdanau, Cho, and Bengio 2014), comprising of an encoder recurrent neural network (RNN) to process the input and a decoder RNN with attention that generates the output. The network is trained to predict an erroneous program location along with the correct statement. DeepFix invokes it iteratively to fix multiple errors in the program one-by-one.

Statistical Inference under Privacy Constraints
Relevant lab: Information Theory Lab (Prof. Himanshu Tyagi)
Independent samples from an unknown probability distribution p on a domain of size k are distributed across n players, with each player holding one sample. Each player can communicate ` bits to a central referee in a simultaneous message passing model of communication to help the referee infer a property of the unknown p. What is the least number of players for inference required in the communication-starved setting of l < log k? We begin by exploring a general simulate-and-infer strategy for such inference problems where the center simulates the desired number of samples from the unknown distribution and applies standard inference algorithms for the collocated setting. Our first result shows that for l < log k perfect simulation of even a single sample is not possible. Nonetheless, we present next a Las Vegas algorithm that simulates a single sample from the unknown distribution using no more than O(k/2^l) samples in expectation. As an immediate corollary, it follows that simulate-and-infer attains the optimal sample complexity of Θ(k^2/2^lε^2) for learning the unknown distribution to an accuracy of ε in total variation distance.
For the prototypical testing problem of identity testing, simulate-and-infer works with O(k^(3/2)/2^lε^2) samples, a requirement that seems to be inherent for all communication protocols not using any additional resources. Interestingly, we can break this barrier using public coins. Specifically, we exhibit a public-coin communication protocol that accomplishes identity testing using O(k/√2^lε^2) samples. Furthermore, we show that this is optimal up to constant factors. Our theoretically sample-optimal protocol is easy to implement in practice. Our proof of lower bound entails showing a contraction in χ^2 distance of product distributions due to communication constraints and maybe of interest beyond the current setting.

Strong Converse for Wiretap Channel
Relevant lab: Information Theory Lab (Prof. Himanshu Tyagi)
The strong converse for a coding theorem shows that the optimal asymptotic rate possible with vanishing error cannot be improved by allowing a fixed error. Building on a method introduced by Gu and Effros for centralized coding problems, we develop a general and simple recipe for proving strong converse that is applicable for distributed problems as well. Heuristically, our proof of strong converse mimics the standard steps for proving a weak converse, except that we apply those steps to a modified distribution obtained by conditioning the original distribution on the event that no error occurs. A key component of our recipe is the replacement of the hard Markov constraints implied by the distributed nature of the problem with a soft information cost using a variational formula introduced by Oohama. We illustrate our method by providing a short proof of the strong converse for the Wyner-Ziv problem and new strong converse theorems for interactive function computation, common randomness and secret key agreement, and the wiretap channel.

Universal Multiparty Secret Key Agreement
Relevant lab: Information Theory Lab (Prof. Himanshu Tyagi)
Multiple parties observing correlated data seek to recover each other’s data and attain omniscience. To that end, they communicate interactively over a noiseless broadcast channel – each bit transmitted over this channel is received by all the parties. We give a universal interactive communication protocol, termed the recursive data exchange protocol (RDE), which attains omniscience for any sequence of data observed by the parties and provide an individual sequence guarantee of performance. As a by-product, for observations of length n, we show the universal rate optimality of RDE up to an O(√(log n)/√n) term in a generative setting where the data sequence is independent and identically distributed (in time). Furthermore, drawing on the duality between omniscience and secret key agreement due to Csiszar and Narayan, we obtain a ´ universal protocol for generating a multiparty secret key of rate at most O(√(log n)/√n) less than the maximum rate possible. A key feature of RDE is its recursive structure whereby when a subset A of parties recover each-other’s data, the rates appear as if the parties have been executing the protocol in an alternative model where the parties in A are collocated.
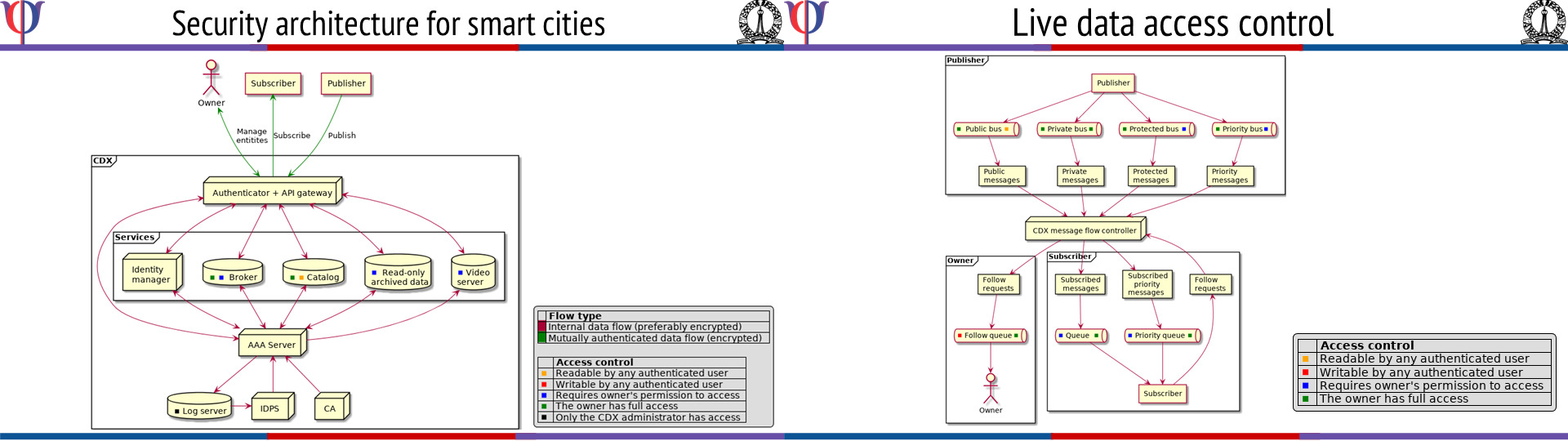
Security for Smart Cities
Relevant lab: Robert Bosch Center for Cyber-Physical Systems
[Text borrowed from http://www.rbccps.org/smart-city/]
The Indian Government has identified Smart Cities as a priority area for development in the coming years. ICT will play a key role in supporting smart city solutions and more specifically, IoT technologies will be a key enabler for providing the “smarts”. The requirements from citizens in cities is diverse and cuts across many different verticals like transportation, water management, solid waste management, smart parking etc. Typically, each vertical will be addressed by a different vendor, who will provide an end-to-end solution. However it has been recognized of late, that a better approach might be to have a horizontal approach where in sensors, and other data are made available across different silos – in order to foster new, cost effective solutions to various city related problems and citizen needs. A simple example is that of a camera sensor which can aid in not only in surveillance but also in crowd management, smart parking, transit operations management etc. applications. Hence there is a need to develop smart city ICT/IoT framework as a generic platform that will support a diverse set of applications.
The main thrust of this work will be to develop an instrumented test bed in the IISc campus, which will consist of a collection of sensors, gateways, middleware and server side software, supporting a few candidate applications of energy monitoring, water monitoring and solid waste management. The testbed will be a hybrid of real and virtual components. Being able to support such a hybrid system will enable us to test concepts at scales of real cities with 1000s of gateways and 10s of thousands of sensors, while the real world portion of the testbed will still be small and low cost. The scaling limits will be determined via analysis of current and future requirements for Indian Smart Cities in terms of:
- Data base size, query latency, IO/second, availability
- Communication throughput, latency, loss tolerance
- Gateway performance (throughput), memory, storage,
- Sensor density per square kilometer and its data bandwidth
- Finally the test bed will be validated via the physical portions instantiated in the IISc campus as well as the virtual portions instantiated to mimic a city of the scale of Bangalore. The concept of using light poles as smart city infrastructures will also be incorporated in the test bed via instrumenting about 10 light poles on the campus, with the gateways and sensors.
- Allow for experimentation of different technologies at each level of the smart city solutions like:
- Different sensor hardware and firmware stacks, including crowd sourced sensing
- Different wireless front-haul schemes like WiFi, BLE, Sub-GHz
- Different gateway hardware and software stacks to support distributed analytics
- Different edge and cloud computing architectures
- Different data persistence platforms including in-memory DB, time-series DB, and NoSQL
- Different realtime and batch analytics platforms
- Support for metrics at various levels from the sensors to the server, both in hardware and software to enable a quantitative assessment of the performance of various alternative approaches. We believe that this activity will open up opportunities to explore new concepts like gateway virtualization, virtual agents, dynamic resource management, etc. in the second year onwards.
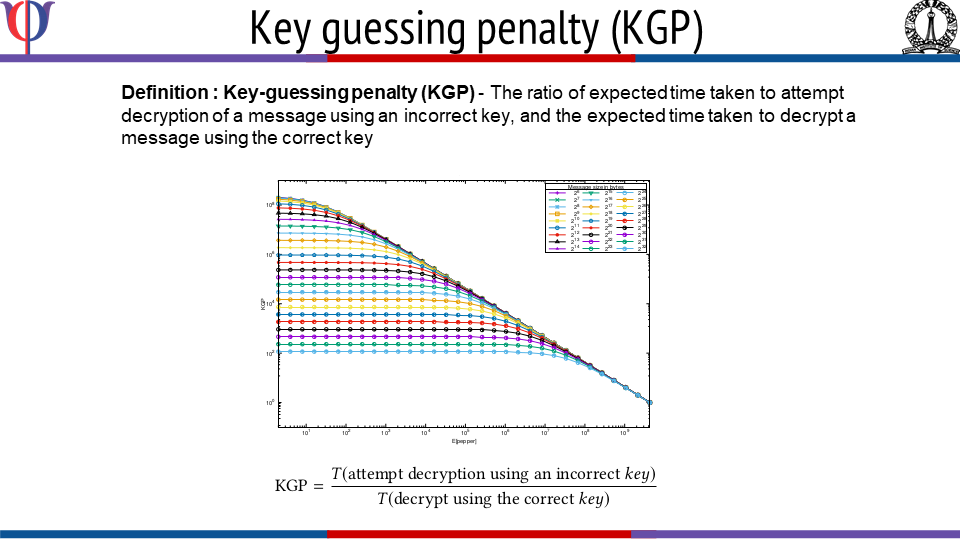
FreeStyle: Customizable, Randomized, and Variable Round Version of Chacha Cipher to Resist Offline Key-guessing
Relevant lab: Robert Bosch Center for Cyber-Physical Systems
This work introduces Freestyle, a highly customizable, randomized, and variable round version of the ChaCha cipher. Freestyle uses the concept of hash based halting condition where a decryption attempt with an incorrect key is likely to take longer time to halt. This makes Freestyle resistant to key-guessing attacks i.e. brute-force and dictionary based attacks. Freestyle demonstrates a novel approach for ciphertext randomization by using random number of rounds for each block, where the exact number of rounds are unknown to the receiver in advance. Freestyle provides the possibility of generating up to 2^256 different ciphertexts for a given key, nonce, and message; thus resisting key and nonce reuse attacks. Due to its inherent random behavior, Freestyle makes cryptanalysis through known-plaintext, chosen-plaintext, and chosen-ciphertext attacks difficult in practice. On the other hand, Freestyle’s customization makes it suitable for both low-security and security-critical applications. Freestyle is ideal for applications that: (i) favor ciphertext randomization and resistance to key-guessing and key reuse attacks; and (ii) situations where ciphertext is in full control of an adversary for carrying out an offline key-guessing attack.
Differentially-Private Algorithms for Consensus and Convex Optimization
Relevant lab: Control and Network Systems Group (Prof. Pavan Kumar Tallapragada)
Privacy, and the related issue of security, in CPS is of critical importance in preventing catastrophic failures. As demonstrated by some high profile cyber attacks, privacy and security in CPS is a complex problem and requires a multi-layered solution. One such layer must be at the level of control and communication itself - instead of securing the operation of CPS independently after the design of control and communication policies, an integrated approach must be taken. In this theme, this work makes two contributions.
The first contribution is a differentially private algorithm for multi-agent average consensus. In the first problem, the agents seek to converge to the average of their initial values while keeping this information differentially private from an adversary that has access to all the messages. Our algorithm converges almost surely to an unbiased estimate of the average of agents’ initial states. We formally characterize its differential privacy properties. We show that the optimal choice of our design parameters (with respect to the variance of the convergence point around the exact average) corresponds to a one-shot perturbation of initial states.
The second contribution is a differentially private algorithm for distributed convex optimization, wherein a group of agents aim to minimize the sum of individual objective functions while each desires that any information about its objective function is kept private. We proved the impossibility of achieving differential privacy using strategies based on perturbing the inter-agent messages with noise when the underlying noise-free dynamics are asymptotically stable. This justifies our algorithmic solution based on the perturbation of individual functions with Laplace noise. To this end, we establish a general framework for differentially private handling of functional data. We further design post-processing steps that ensure the perturbed functions regain the smoothness and convexity properties of the original functions while preserving the differentially private guarantees of the functional perturbation step. This methodology allows us to use any distributed coordination algorithm to solve the optimization problem on the noisy functions. Finally, we explicitly bound the magnitude of the expected distance between the perturbed and true optimizers which leads to an upper bound on the privacy- accuracy trade-off curve.
References:
- E. Nozari, P. Tallapragada, J. Cortes, "Differentially private average consensus: obstructions, trade-offs, and optimal algorithm design," Automatica, vol. 81, pp. 221-231, 2017
- E. Nozari, P. Tallapragada, J. Cortes, "Differentially private distributed convex optimization via functional perturbation," IEEE Transactions on Control of Network Systems, vol. 5, no. 1, pp. 395-408, 2018
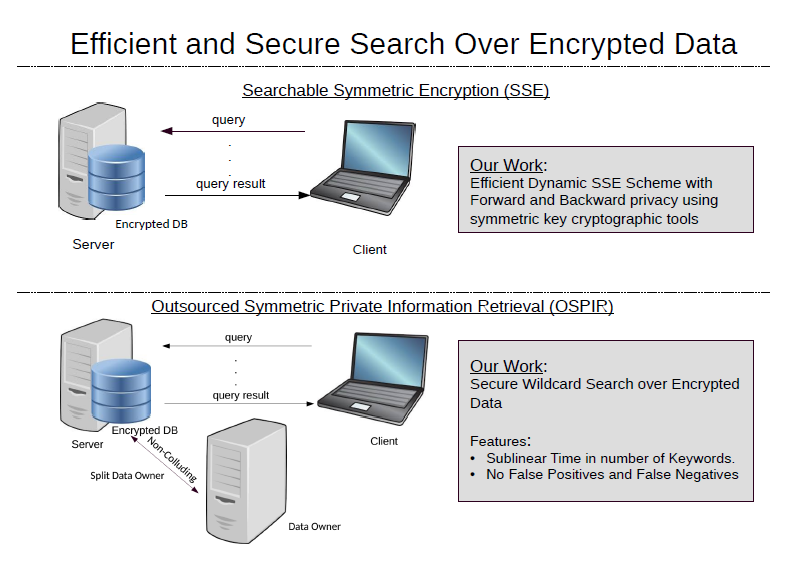
Efficient and Secure Search over Encrypted Data
Relevant lab: Informatics and Security Lab (Prof. Sanjit Chatterjee)
Due to a variety of crucial benefits, enterprises outsource their data to cloud resident storage. If the outsourced data is stored as plaintext on remote servers then it may be intercepted by adversaries. Hence, data is stored in encrypted form on remote servers. However, if the client has to decrypt the data in order to get results for a search query, it defeats the purpose of outsourcing data. Generic tools such as fully homomorphic encryption or oblivious RAM can be considered to construct protocols that leak almost no information to the server. But as of now, these tools are costly for large databases and hence, are impractical. A practical solution to this problem is Searchable Symmetric Encryption (SSE) schemes that trade efficiency for security. The focus of our research in this area is to build efficient and secure dynamic searchable encryption scheme, protocol for wildcard search over encrypted data etc.
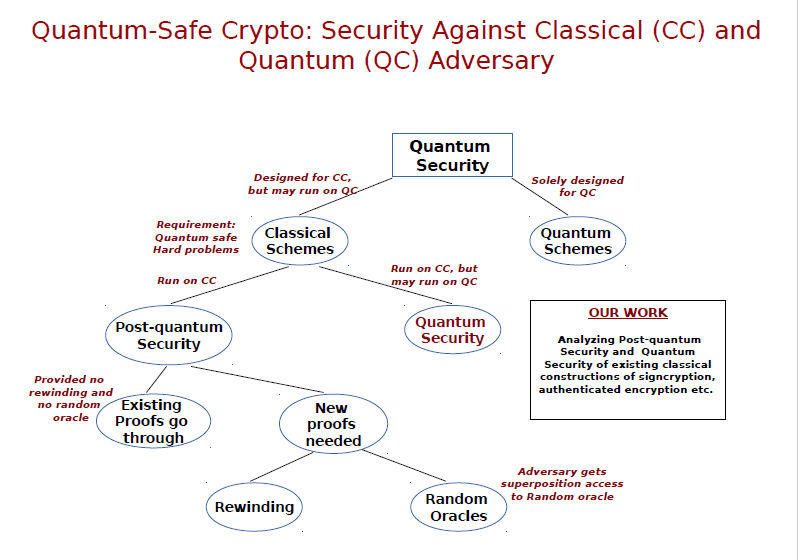
Quantum-safe Cryptography
Relevant lab: Informatics and Security Lab (Prof. Sanjit Chatterjee)
The possible advent of quantum computers in the foreseeable future poses a threat to the security of many classical cryptosystems. Recently, NIST announced the Post-Quantum Crypto project to standardize the quantum-resistant public-key cryptographic algorithms. Research in this area has broadly two aspects: (i) designing crypto primitives based on certain number theoretic problems which are believed to be intractable even in the presence of a full-scale quantum computer and (ii) defining appropriate security model that captures the power of quantum computers and arguing security of crypto-systems in that model. Our group is actively working on both the above aspects. We are currently investigating isogeny maps defined over elliptic curve groups to build quantum-safe primitives as well as looking at formal security of signcryption and authenticated encryption in a quantum world.

Non-malleable Randomness Encoders
Relevant lab:Cryptography, Security and Privacy Group (Prof. Bhavana Kanukurthi)
Non-malleable Codes (NMCs), introduced by Dziembowski, Peitrzak and Wichs (ITCS 2010), serve the purpose of preventing ``related tampering'' of encoded messages. The most popular tampering model considered is the $2$-split-state model where a codeword consists of 2 states, each of which can be tampered independently. While NMCs in the $2$-split state model provide the strongest security guarantee, despite much research in the area we only know how to build them with poor rate ($\Omega(\frac{1}{logn})$, where $n$ is the codeword length). However, in many applications of NMCs one only needs to be able to encode randomness i.e., security is not required to hold for arbitrary, adversarially chosen messages. For example, in applications of NMCs to tamper-resilient security, the messages that are encoded are typically randomly generated secret keys. To exploit this, in this work, we introduce the notion of Non-malleable Randomness Encoders (NMREs) as a relaxation of NMCs in the following sense: NMREs output a random message along with its corresponding non-malleable encoding.
Our main result is the construction of a $2$-split state, rate-$\frac{1}{2}$ NMRE. While NMREs are interesting in their own right and can be directly used in applications such as in the construction of tamper-resilient cryptographic primitives, we also show how to use them, in a black-box manner, to build a $3$-split-state (standard) NMCs with rate $\frac{1}{3}$. This improves both the number of states, as well as the rate, of existing constant-rate NMCs.

Constant-rate Non-malleable Codes
Relevant lab:Cryptography, Security and Privacy Group (Prof. Bhavana Kanukurthi)
Non-malleable codes (NMCs), introduced by Dziembowski, Pietrzak and Wichs (ITCS 2010), generalize the classical notion of error correcting codes by providing a powerful guarantee even in scenarios where error correcting codes cannot provide any guarantee: a decoded message is either the same or completely independent of the underlying message, regardless of the number of errors introduced into the codeword. Informally, NMCs are defined with respect to a family of tampering functions F and guarantee that any tampered codeword either decodes to the same message or to an independent message, so long as it is tampered using a function $f \in F$.
Nearly all known constructions of NMCs are for the t-split-state family, where the adversary tampers each of the t states of a codeword, arbitrarily but independently. Cheraghchi and Guruswami (TCC 2014) obtain a Rate-1 non-malleable code for the case where $t = O(n)$ with $n$ being the codeword length and, in (ITCS 2014), show an upper bound of $1-1/t$ on the best achievable rate for any $t-$split state NMC. For $t=10$, Chattopadhyay and Zuckerman (FOCS 2014) achieve a constant rate construction where the constant is unknown. In summary, there is no known construction of an NMC with an explicit constant rate for any $t= o(n)$, let alone one that comes close to matching Cheraghchi and Guruswami's lowerbound!
In this work, we construct an efficient non-malleable code in the $t$-split-state model, for $t=4$, that achieves a constant rate of $\frac{1}{3+z}$, for any constant $z > 0$, and error $2^{-\Omega(p / log^{c+1} p)}$, where $p$ is the length of the message and $c > 0$ is a constant.